SVS Model Details
| Category | Model | Architecture / Features | Implementation Details |
|---|---|---|---|
| Discriminative | HTDemucs |
|
Training details:
|
| Mel-RoFo. (L) |
|
Pre-trained on undisclosed larger dataset. Settings per [30]. | |
| Mel-RoFo. (S) |
| Training details:
|
|
| Generative | SGMSVS |
|
Training details:
|
| Mel-RoFo. (S) + BigVGAN |
|
BigVGAN finetuning details
|
Metric Details
| Type | Metric | Metric Information | Implementation Notes |
|---|---|---|---|
| Intrusive | BSS‑Eval:
|
Blind Source Separation Evaluation (BSS-Eval) metrics are energy‑ratio measures between reference and separated signal, the where estimation is decomposed into individual components via projections onto FIR-filtered subspaces of target and distorting sources [4]. | The used packages/toolkits to compute the metrics are listed below:
|
PEASS:
|
The Perceptual Evaluation methods for Audio Source Separation (PEASS) also decompose a signal into distortion components. However, before decomposition, the signal is split into gammatone subbands and segemented into overlapping frames. Then regression is used approximate subjective ratings [12]. |
|
|
| ViSQOL | Similar to PEASS, the Virtual Speech Quality Objective Listener (ViSQOL), employs a perceptual model with a fitted mapping on a spectro-temporal representation. |
|
|
| \( \mathcal{L}_{\text{MR}} \) | The Multi-resolution STFT Loss (\( \mathcal{L}_{\text{MR}} \)) is computed by averaging the STFT loss denoted in the paper over 5 STFT resolutions (256, 512, 1024, 2048, 4096). |
|
|
| Embedding-based Intrusive | Embedding‑MSE
|
MSE between time-resolved Self-Supervised Learning (SSL) embeddings which are: Large-scale Contrastive Language-Audio Pretraining audio (CLa) and music (CLm) embeddings [15], the 12th layer embeddings of an acoustic Music undERstanding model with large-scale self-supervised Training (MERT-L12/M-L12) [26], and Music2Latent (M2L) embeddings [17] |
|
Intrusive Variant of Fréchet Audio Distance (FADsong2song)
|
Fréchet distance between Gaussian fits of embedding distributions. The distributions are individually fitted to the time-resolved embeddings. The same embeddings as used for the MSE calculationen are used (CLa, CLm, M-L12, M2L). |
|
|
| Non-Intrusive | XLS‑R‑SQA | MOS-like speech enhancement quality that generalizes well on unseen data. |
|
Audiobox‑Aesthetics
|
Universal MOS-like audio quality assessment model for speech, music and sound. In total 4 evaluation axes exist, we analyzed 2 in our paper (PQ and CU). |
|
|
| PAM | Another non-intrusive universal MOS-like metric that prompts audio-language models for audio quality assessment (PAM). |
|
|
| SingMOS | wav2vec 2.0‑based MOS predictor for singing voice. Trained on MOS ratings of singing voice audio incl. examples from singing voice conversion and coding models. |
|
Audio Examples
| File-ID | Mixture | Target | HTDemucs | Mel-RoFo. (S) | Mel-RoFo. (L) | SGMSVS | Mel-RoFo. (S) + BigVGAN |
|---|---|---|---|---|---|---|---|
| #1 | DMOS: 3.08 | DMOS: 2.83 | DMOS: 3.67 | DMOS: 3.25 | DMOS: 4.17 | ||
| #2 | DMOS: 3.58 | DMOS: 2.33 | DMOS: 3.58 | DMOS: 3.33 | DMOS: 4.08 | ||
| #3 | DMOS: 1.83 | DMOS: 3.08 | DMOS: 3.75 | DMOS: 4.25 | DMOS: 4.17 | ||
| #5 | DMOS: 2.42 | DMOS: 2.92 | DMOS: 2.75 | DMOS: 3.50 | DMOS: 2.92 | ||
| #6 | DMOS: 1.00 | DMOS: 1.17 | DMOS: 1.42 | DMOS: 1.08 | DMOS: 1.58 | ||
| #10 | DMOS: 2.75 | DMOS: 4.00 | DMOS: 3.92 | DMOS: 4.83 | DMOS: 4.17 | ||
| #14 | DMOS: 1.58 | DMOS: 2.17 | DMOS: 2.83 | DMOS: 1.58 | DMOS: 3.25 | ||
| #21 | DMOS: 2.92 | DMOS: 2.75 | DMOS: 3.17 | DMOS: 3.50 | DMOS: 3.67 | ||
| #22 | DMOS: 1.58 | DMOS: 2.67 | DMOS: 3.42 | DMOS: 2.58 | DMOS: 3.25 | ||
| #31 | DMOS: 2.50 | DMOS: 2.75 | DMOS: 3.75 | DMOS: 2.50 | DMOS: 3.67 | ||
| #42 | DMOS: 3.33 | DMOS: 4.00 | DMOS: 4.25 | DMOS: 4.67 | DMOS: 4.58 | ||
| #44 | DMOS: 3.08 | DMOS: 3.58 | DMOS: 4.50 | DMOS: 4.17 | DMOS: 4.25 |
Exemplary Metric Rankings Compared to DMOS Ranking
The color gradients below encode the rankings of the audio files according to the corresponding metrics/scores. The rankings are sorted according to the DMOS ranking. A color gradient from dark green to dark red similar to the gradient present for DMOS would indicate a higher correlation between the metric and DMOS.Discriminative Models (150 audio files)
| SINGMOS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SDR | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MUSIC2LATENT MSE | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MERT-L12 MSE | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DMOS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rank #1 | rank #150 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Generative Models (100 audio files)
| SINGMOS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SDR | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MUSIC2LATENT MSE | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MERT-L12 MSE | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DMOS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rank #1 | rank #100 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
DMOS & Correlation Results
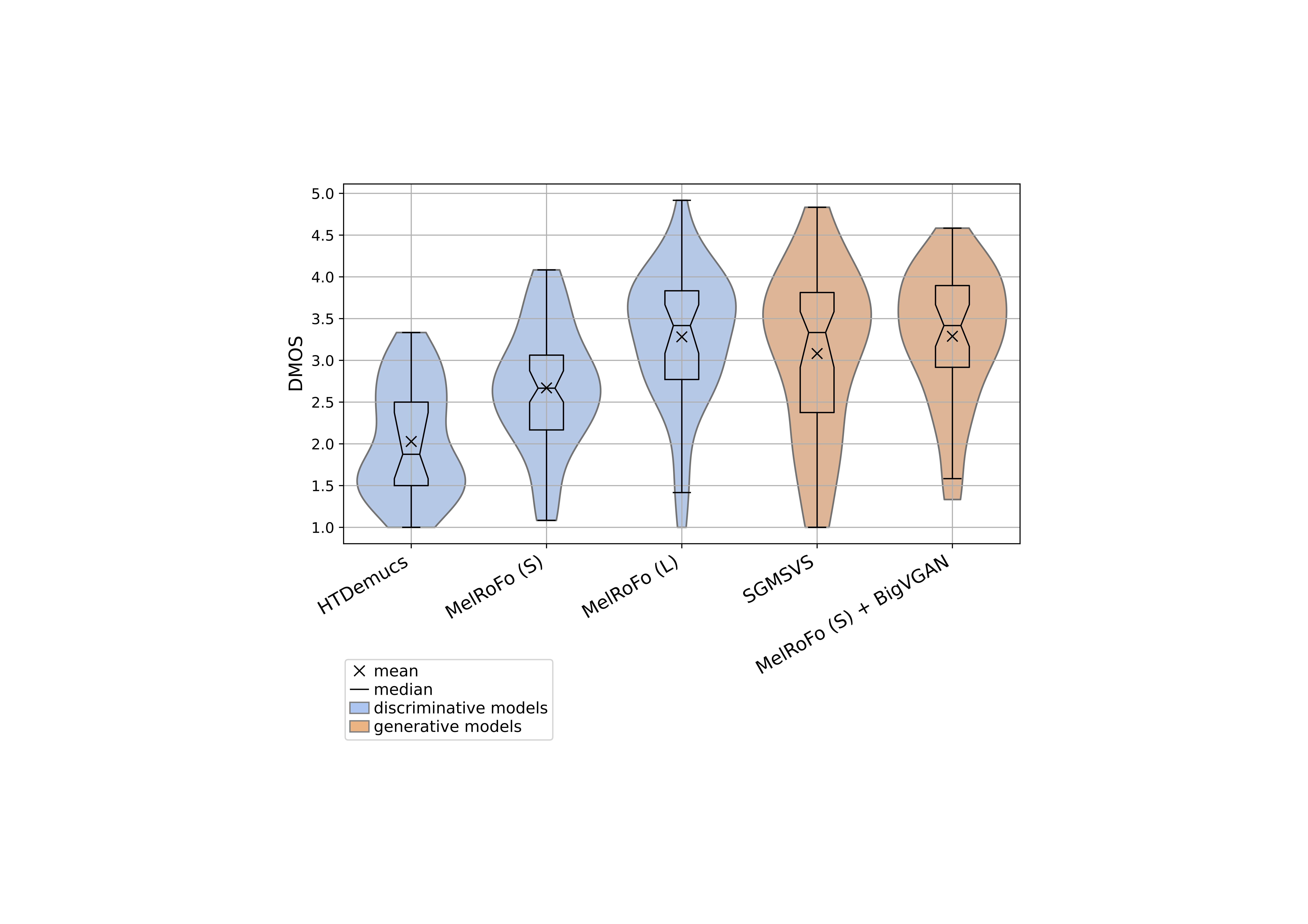
Degradation Mean Opinion Score (DMOS) obtained from ITU P.808 compliant Degradation Category Rating (DCR) listening test.
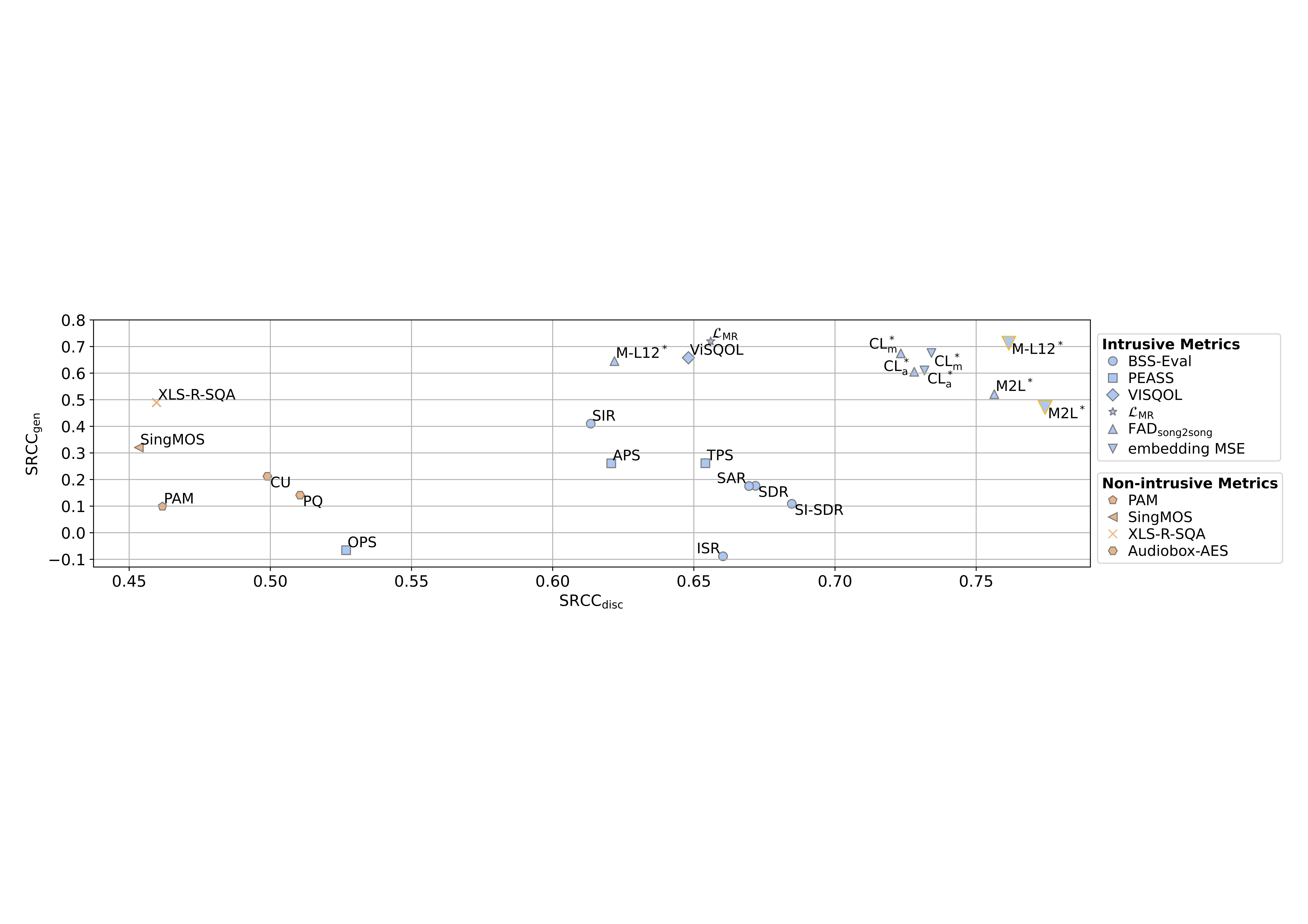
Trade-off between Spearman’s rank correlation coefficients of objective metrics and DMOS for evaluation of discriminative (SRCCdisc) and generative models (SRCCgen).
Citation (BibTeX)
If you use any parts of our code, our data or the gensvs package in your work, please cite our paper and the work that formed the basis of this research.
@INPROCEEDINGS{11230934,
author={Bereuter, Paul A. and Stahl, Benjamin and Plumbley, Mark D. and Sontacchi, Alois},
booktitle={2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
title={Towards Reliable Objective Evaluation Metrics for Generative Singing Voice Separation Models},
year={2025},
volume={},
number={},
pages={1-5},
keywords={Measurement;Degradation;Training;Time-frequency analysis;Correlation;Limiting;Computational modeling;Conferences;Reliability;Software development management},
doi={10.1109/WASPAA66052.2025.11230934}}