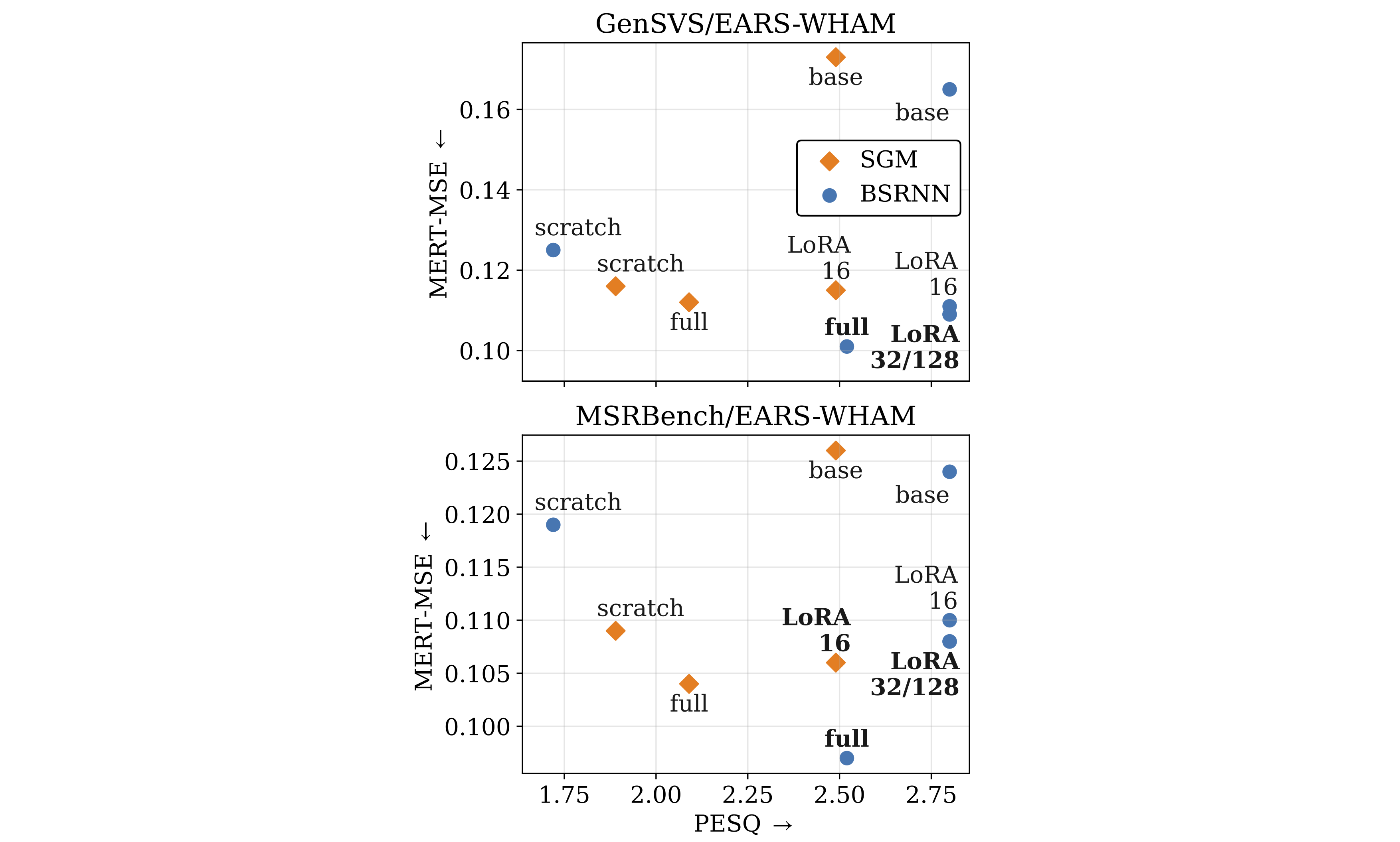
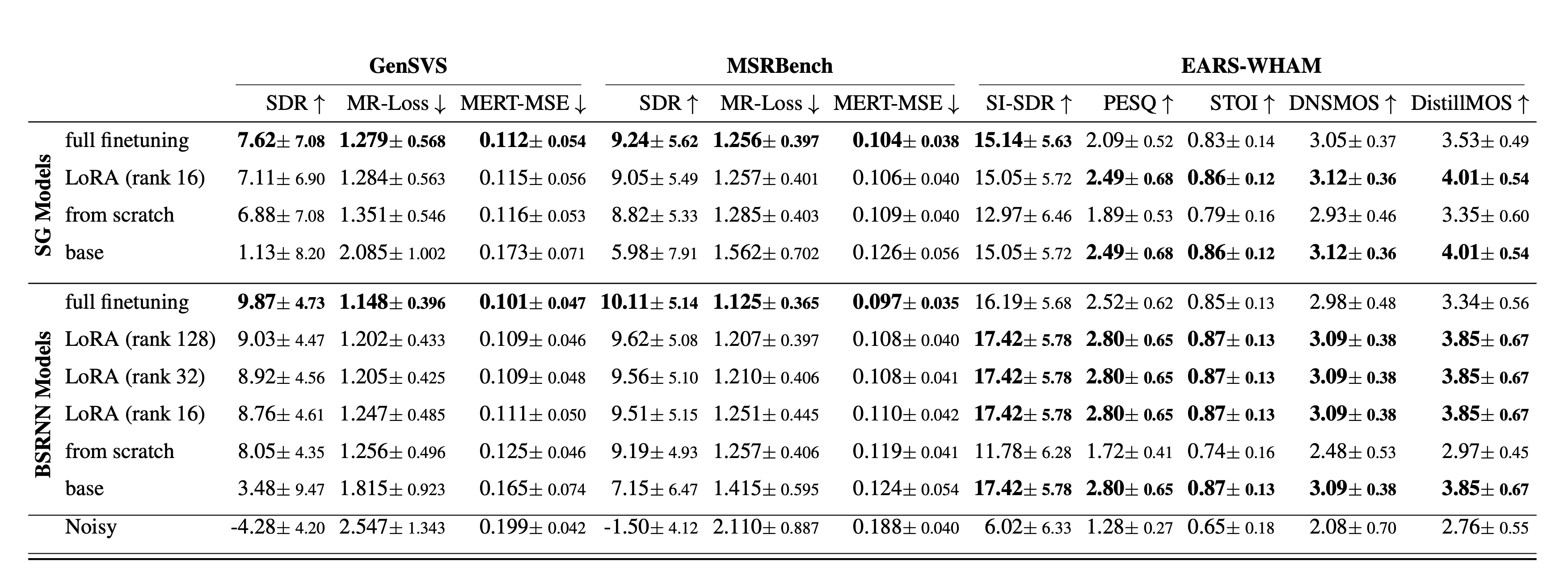
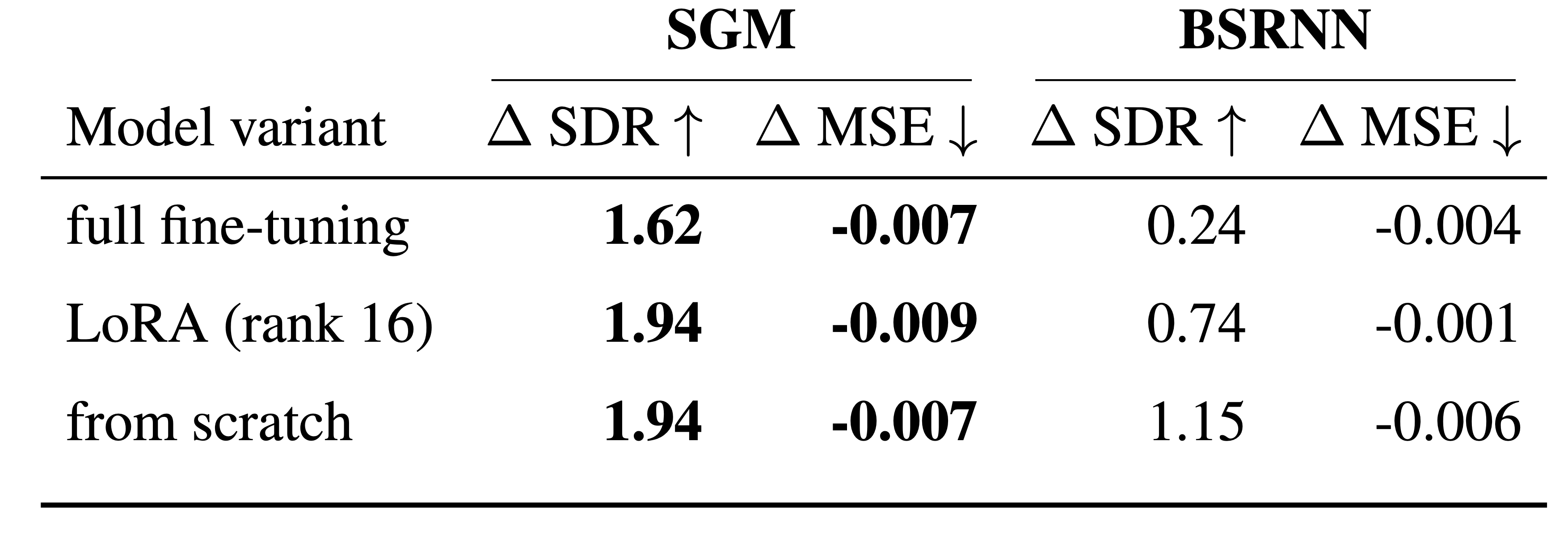
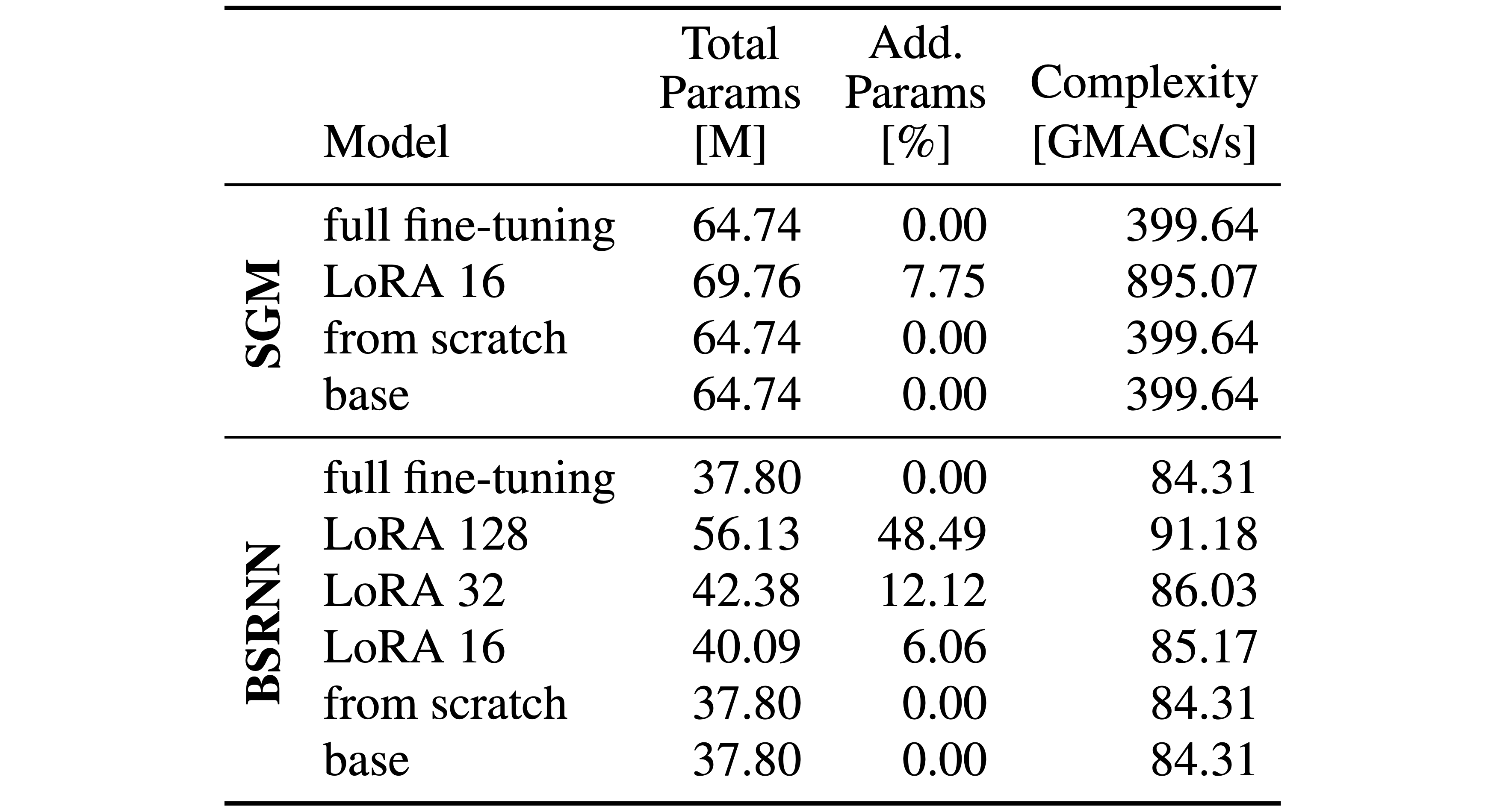
State-of-the-art speech enhancement (SE) models benefit from large-scale labeled datasets, whereas singing voice separation (SVS) models suffer from limited available training data. To address this limitation, we formulate singing voice separation as domain adaptation from speech enhancement to singing voice separation. We investigate two fine-tuning strategies: full fine-tuning and parameter-efficient fine-tuning using Low-Rank Adaptation (LoRA) on a generative and a discriminative model. Models with either adaptation strategy outperform the same architectures trained from scratch by 0.2-1.8 dB in Signal-to-Distortion-Ratio (SDR). Full fine-tuning yields highest singing voice separation performance, but catastrophic forgetting degrades speech enhancement performance. LoRA fine-tuning achieves competitive singing voice separation performance while preserving the original speech enhancement capability with only 6-12% additional parameters compared to the base speech enhancement model. Furthermore, the generative model shows improved generalization to an unseen test set. The results demonstrate that adapting pretrained speech enhancement models is an effective strategy for training singing voice separation models in data-scarce scenarios.
The audio examples on this webpage accompany our paper titled "Teaching Speech Enhancement Models to Sing: Domain Adaptation from Speech Enhancement to Singing Voice Separation" presented at _____ in 2026. The audio audible here is the output of models that were trained with from scratch training, LoRA, or full fine-tuning for the task of singing voice separation. Only the base model and the LoRA model with disabled adapter, which is effectively the base speech enhancement model, are models trained only for speech enhancement.
| Sample 1 | Sample 35 | Sample 42 | ||
|---|---|---|---|---|
| Mixture | ||||
| Target | ||||
| BSRNN | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| LoRA (rank 32) | ||||
| LoRA (rank 128) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [2] | ||||
| SGM | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [3] | ||||
| Sample 240 | Sample 198 | Sample 78 | ||
|---|---|---|---|---|
| Mixture | ||||
| Target | ||||
| BSRNN | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| LoRA (rank 32) | ||||
| LoRA (rank 128) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [2] | ||||
| SGM | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [3] | ||||
| p102 / 0007 | p105 / 00164 | p104 / 00749 | ||
|---|---|---|---|---|
| Mixture | ||||
| Target | ||||
| BSRNN | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| LoRA (rank 32) | ||||
| LoRA (rank 128) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [2] | ||||
| SGM | Full fine-tuning | |||
| LoRA (rank 16) | ||||
| From scratch | ||||
| LoRA (rank 16) (adapter disabled) | ||||
| Base [3] | ||||
If you use any parts of our code, our data or the gensvs package in your work, please cite our paper and the work that formed the basis of this research.
@INPROCEEDINGS{bereuter2026se2svs,
author={Bereuter, Paul A. and Plumbley, Mark D. and Sontacchi, Alois},
booktitle={},
title={Teaching Speech Enhancement Models to Sing: Domain Adaptation from Speech Enhancement to Singing Voice Separation},
year={2026},
volume={},
number={},
pages={},
keywords={},
doi={}